 В современных условиях значимость грамотного управления инфраструктурой сетевых технологий сложно переоценить. Каждый элемент системы требует тщательного наблюдения и анализа, чтобы обеспечить бесперебойное функционирование и высокую производительность. Это особенно актуально в контексте обеспечения безопасности и устойчивости всей сети.
В современных условиях значимость грамотного управления инфраструктурой сетевых технологий сложно переоценить. Каждый элемент системы требует тщательного наблюдения и анализа, чтобы обеспечить бесперебойное функционирование и высокую производительность. Это особенно актуально в контексте обеспечения безопасности и устойчивости всей сети.
Правильная оценка состояния ключевых компонентов помогает выявить потенциальные проблемы на ранних стадиях и минимизировать риски, связанные с сбоями в работе. Использование современных методов анализа и инструментов позволяет не только следить за функционированием, но и оптимизировать работу сети, что является залогом эффективного бизнеса.
В данной статье мы рассмотрим подходы к анализу и оценке состояния ключевых элементов сетевой инфраструктуры. Обсудим методы, которые помогут вам обеспечить стабильную работу системы, а также инструменты, позволяющие сделать процесс управления более прозрачным и предсказуемым. Внимание к деталям и системный подход в этом вопросе могут значительно повысить уровень надежности вашей IT-инфраструктуры.
Значение мониторинга для ИТ-инфраструктуры
В современном мире информационных технологий контроль за состоянием систем и сетей становится неотъемлемой частью эффективного управления. Поддержание стабильной работы компонентов ИТ-структуры, таких как серверы, приложения и сетевые устройства, напрямую влияет на производительность бизнеса и уровень удовлетворенности пользователей. Понимание текущего состояния инфраструктуры и раннее выявление потенциальных проблем позволяют избежать серьезных сбоев и минимизировать потери.
Регулярная оценка состояния компонентов системы позволяет не только выявлять неисправности, но и анализировать производительность, что способствует более эффективному использованию ресурсов. Проактивный подход в этом процессе помогает в оптимизации затрат и улучшении качества обслуживания. Это особенно важно для организаций, стремящихся к высокой доступности своих сервисов и приложений.
Кроме того, систематическое наблюдение за состоянием ИТ-ресурсов помогает в соблюдении требований безопасности. Непредвиденные сбои или атаки могут привести к утечкам данных и другим негативным последствиям, поэтому выявление уязвимостей на ранних стадиях имеет критическое значение. Эффективное управление рисками и соблюдение стандартов безопасности становится возможным только при наличии постоянного контроля за системой.
Основные компоненты контроллера домена
В современных информационных системах существуют ключевые элементы, которые обеспечивают стабильную работу сетевой инфраструктуры. Эти компоненты играют важную роль в управлении пользователями, ресурсами и безопасностью, обеспечивая эффективное взаимодействие всех участников сети. Понимание их функций и взаимосвязей помогает организовать надежную и продуктивную среду для работы.
Первым важным элементом является служба каталогов, которая отвечает за хранение и управление данными о пользователях, устройствах и других ресурсах. Эта структура позволяет быстро находить необходимую информацию и осуществлять поиск по различным критериям. Она служит основой для аутентификации и авторизации пользователей в сети.
Следующий компонент – это механизмы управления доступом, которые определяют, кто и каким образом может взаимодействовать с ресурсами системы. Эти системы обеспечивают безопасность, устанавливая права и ограничения для пользователей, что способствует предотвращению несанкционированного доступа и утечек информации.
Также важен механизм репликации, который обеспечивает синхронизацию данных между различными экземплярами службы каталогов. Это позволяет сохранить целостность и актуальность информации в распределенных сетях, уменьшая риск потери данных и обеспечивая их доступность в любой момент времени.
Не менее значимой является система управления политиками, которая задает правила и параметры конфигурации для устройств и пользователей в сети. Эти политики помогают стандартизировать настройки, упрощая управление и поддержание безопасности на всех уровнях.
Методы сбора данных о ресурсах
Эффективное управление сетевыми объектами требует точного и своевременного получения информации о состоянии различных компонентов системы. Существует множество подходов к сбору данных, каждый из которых имеет свои особенности и преимущества. Рассмотрим основные методы, позволяющие получить необходимую информацию для анализа и оптимизации работы системы.
Одним из популярных способов является использование специализированного программного обеспечения, которое автоматизирует процесс сбора и обработки данных. Эти инструменты могут выполнять задачи, такие как:
- Сбор показателей производительности системных ресурсов;
- Отслеживание событий и уведомлений;
- Анализ журналов и логов.
Другим важным методом является применение встроенных утилит операционной системы, которые позволяют получать актуальные данные без необходимости установки дополнительного ПО. К таким утилитам относятся:
- Task Manager: предоставляет информацию о запущенных процессах и их ресурсном использовании.
- Performance Monitor: позволяет настраивать сбор данных о производительности и отображать их в реальном времени.
- Windows Event Viewer: помогает анализировать системные события и ошибки.
Также стоит отметить использование сетевых протоколов для сбора информации. Например, SNMP (Simple Network Management Protocol) позволяет организовать централизованный сбор данных о состоянии сетевых устройств и серверов. Данный протокол обеспечивает:
- Универсальность в взаимодействии с различными устройствами;
- Эффективное управление сетевыми ресурсами;
- Систематический анализ данных.
Наконец, важным аспектом является ручной сбор данных, который может быть полезен в ситуациях, когда автоматизированные методы не дают нужных результатов. Это может включать в себя:
- Проверку конфигурационных файлов;
- Анализ сетевых подключений;
- Обсуждение с пользователями о возникших проблемах.
Сочетание этих методов позволяет получить полное представление о состоянии системы, что является основой для дальнейших действий по оптимизации и улучшению её работы.
Инструменты для мониторинга системы
Эффективное управление IT-инфраструктурой невозможно без применения современных решений для мониторинга ресурсов контроллера домена, оценки состояния и производительности системы. Существует множество инструментов, которые помогают в выявлении проблем и оптимизации работы. Эти программы позволяют получить полное представление о текущем состоянии компонентов, а также анализировать тенденции и предсказывать возможные сбои.
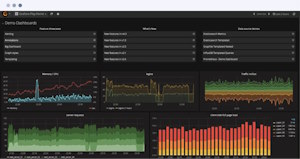
Системы визуализации предоставляют пользователю интуитивно понятные графики и дашборды, что облегчает восприятие данных. Они помогают быстро оценить общее состояние сети, определить узкие места и повысить эффективность управления.
Агентские решения устанавливаются на отдельные машины и обеспечивают сбор и отправку информации на центральный сервер. Эти агенты собирают данные о процессах, загрузке памяти и работе приложений, позволяя детально анализировать поведение системы в реальном времени.
Кроме того, инструменты для аудита могут существенно упростить задачу отслеживания изменений в конфигурациях и настройках. Они позволяют фиксировать каждое изменение, обеспечивая высокий уровень прозрачности и контроль за выполнением политик безопасности.
Системы управления событиями собирают и анализируют журналы различных компонентов, помогая выявлять аномалии и угрозы. Их использование значительно снижает время реакции на инциденты и повышает общую безопасность инфраструктуры.
Наконец, важно отметить, что интеграция с облачными сервисами открывает новые возможности для гибкости и масштабируемости. Используя облачные решения, организации могут более эффективно управлять своими ресурсами, получать доступ к аналитическим инструментам и обеспечивать высокую доступность сервисов.
Таким образом, разнообразие доступных инструментов позволяет каждому администратору выбрать оптимальные решения для анализа и управления системой, обеспечивая стабильную и безопасную работу IT-инфраструктуры.
Анализ производительности и его показатели
Важность оценки эффективности работы систем нельзя недооценивать. Глубокий анализ помогает выявить узкие места и оптимизировать процессы, что в конечном итоге способствует повышению стабильности и скорости функционирования инфраструктуры. Каждый компонент играет свою роль, и понимание их взаимодействия может существенно повлиять на общую производительность.
Основными параметрами, которые следует учитывать при оценке эффективности, являются загрузка процессора, использование оперативной памяти, скорость работы дисковой подсистемы и сетевой трафик. Эти показатели дают возможность получить четкое представление о состоянии системы и определить, где могут возникнуть проблемы.
Загрузка процессора является критически важным показателем, отражающим уровень активности вычислительных ресурсов. Высокая загрузка может указывать на необходимость оптимизации программного обеспечения или добавления дополнительных вычислительных мощностей. Важно не только следить за текущими значениями, но и анализировать их динамику во времени.
Использование оперативной памяти показывает, насколько эффективно система обрабатывает данные. Нехватка памяти может привести к замедлению работы и увеличению времени отклика. Актуальные данные о загрузке памяти помогают понять, требуется ли ее расширение или оптимизация приложений.
Скорость работы дисковой подсистемы влияет на время доступа к данным и общую производительность системы. Регулярный анализ показателей I/O операций позволяет выявить возможные проблемы с хранилищем и предотвратить их негативное влияние на работу приложений.
Наконец, сетевой трафик отражает уровень передачи данных между компонентами системы и внешними ресурсами. Эффективное управление трафиком критично для обеспечения бесперебойной работы. Изучение сетевых показателей помогает выявить узкие места и оптимизировать конфигурацию сети.
Комплексный подход к анализу производительности, включающий все эти аспекты, позволяет не только выявить текущее состояние системы, но и спрогнозировать её будущее развитие. Правильная интерпретация данных и их использование для принятия решений обеспечивает устойчивость и эффективность работы всей инфраструктуры.
Устранение проблем с ресурсами
Для начала важно определить, какие именно аспекты работы системы нуждаются в внимании. Это может быть чрезмерное использование центрального процессора, низкая скорость отклика или сбои в работе служб. Необходимо систематически проверять состояние оборудования, чтобы выявить потенциальные источники проблем. В этом поможет использование специализированных инструментов и утилит, которые позволяют осуществлять глубокий анализ работы компонентов.
После обнаружения неполадок следует проанализировать возможные причины. Часто проблемы могут возникать из-за неэффективного распределения задач, недостатка ресурсов или конфликта между различными процессами. Решения могут включать оптимизацию настроек, пересмотр конфигураций и, при необходимости, обновление оборудования.
Кроме того, регулярное обновление программного обеспечения и систем безопасности поможет предотвратить многие проблемы, связанные с производительностью. Важно также следить за актуальностью драйверов и системных патчей, так как устаревшие версии могут привести к сбоям в работе.
Важным аспектом является и поддержка документации. Ведение записей о произошедших сбоях, методах их устранения и примененных решениях позволит в будущем более быстро реагировать на аналогичные ситуации. Систематизация знаний способствует созданию базы для обучения новых сотрудников и повышения общей компетентности команды.
Таким образом, тщательный подход к выявлению и устранению неполадок, поддержание актуальности системы и внимательное отношение к документированию помогут значительно повысить стабильность и производительность всех компонентов инфраструктуры.
Лучшие практики мониторинга
Эффективное управление вычислительными системами требует регулярного отслеживания их состояния и производительности. Это позволяет заблаговременно выявлять проблемы и минимизировать время простоя. Разработка надежной стратегии контроля за состоянием серверов и сетевых устройств способствует повышению их надежности и устойчивости к сбоям.
1. Установите четкие критерии: Определите ключевые показатели, которые необходимо отслеживать. Это могут быть параметры загрузки процессора, использование памяти, скорость сети и другие важные метрики. Четкие критерии помогут своевременно реагировать на отклонения от нормы.
2. Автоматизация процессов: Используйте автоматизированные инструменты для сбора данных. Это существенно упрощает процесс, позволяет исключить человеческий фактор и обеспечивает регулярность получения информации о состоянии систем.
3. Настройка уведомлений: Важно создать систему оповещений, которая будет информировать вас о критических изменениях. Настройка уведомлений по электронной почте или через мессенджеры поможет оперативно реагировать на возникающие проблемы.
4. Регулярный анализ данных: Периодический анализ собранной информации позволяет выявлять тренды и предсказывать возможные сбои. Используйте визуализацию данных для лучшего понимания состояния систем и их производительности.
5. Обновление и поддержка: Обеспечьте актуальность программного обеспечения и инструментов для контроля. Регулярные обновления не только улучшают функциональность, но и повышают безопасность ваших систем.
6. Документация и обучение: Ведите подробную документацию всех процессов и обучайте сотрудников основам работы с инструментами наблюдения. Это создаст базу знаний, которая поможет эффективно решать возникающие вопросы.
Следуя данным рекомендациям, вы сможете обеспечить надежную работу своих вычислительных систем и минимизировать риски, связанные с их эксплуатацией. Эффективное управление состоянием поможет достигнуть высокой производительности и стабильности в работе.
Будущее мониторинга доменных контроллеров
С развитием технологий наблюдение за работой ключевых элементов информационной инфраструктуры приобретает всё большую значимость. Успешное управление ресурсами требует не только текущего анализа состояния, но и предсказания возможных проблем, что позволяет своевременно принимать меры для их устранения.
Современные инструменты, применяемые для слежения за производительностью систем, уже активно используют методы машинного обучения и искусственного интеллекта. Эти подходы открывают новые горизонты для оптимизации и автоматизации процессов, обеспечивая более глубокое понимание поведения систем и их потребностей.
- Прогнозирование проблем: С помощью анализа больших данных можно заранее определить возможные сбои и неполадки, что существенно снижает риски.
- Автоматизация процессов: Современные решения позволяют автоматизировать реагирование на инциденты, значительно сокращая время на устранение неполадок.
- Интеграция с облачными сервисами: Переход на облачные технологии требует новых подходов к контролю за системами, что подразумевает использование гибридных решений.
Кроме того, важно учитывать рост киберугроз и необходимость обеспечения безопасности. Будущие технологии будут направлены на создание комплексных систем, способных не только отслеживать состояние, но и защищать от возможных атак.
Таким образом, перспективы развития инструментов для наблюдения обещают революционные изменения. Они направлены на создание более умных, безопасных и адаптивных решений, которые смогут предвосхищать потребности пользователей и минимизировать возможные риски. Важно быть готовыми к этим изменениям и адаптироваться к новым реалиям для достижения оптимальных результатов в управлении информационными системами.









